Notes from our lab
A Brief Dive into Go Microservices

Lately we’ve been looking to expand our skills and modernise our tech stack at Brush, and part of that has involved gaining experience with new and diverse programming languages.
As developers, a chief concern is the technical quality of our software, but as a business we also care about the time-cost of our tools. Our main language of choice, Python, offers a lot of valuable and easy-to-use tools and web frameworks with powerful abstractions. However, these can come with unwanted baggage, which can create problems and slow a project down – technical simplicity is one of our core engineering values..
We needed to develop a few quick utility APIs for our customers, so we took the opportunity to take a look at something new.
Why Go?
Go (sometimes known as Golang) has been around since 2012 and has really taken off in recent years. In 2020, it ranked in the top 10 most used languages by professional developers in the State of Developer Ecosystem survey. That’s no small feat considering the ubiquity of languages like JavaScript, Python, Java, and C#. It has fast compile times and great support for modules, IDEs and tooling. It’s responsible for widespread technologies like Docker and Terraform, and sees a lot of use within tech stacks across the globe, including at Google (who developed the language), Microsoft, Netflix, GitHub, and plenty more.
The Plan
We wanted to build a microservice that could provide an email blacklist for our different clients. As anyone with email can tell you, spam messages and other email chicanery are everywhere. While lots of the tools available these days can reduce the incidence of malicious spam through your site (such as reCaptcha preventing bots from spamming signup and contact forms), it’s slightly more annoying to deal with real users entering incorrect addresses by mistake.
One of the easiest ways to deal with this is email verification – where your application requires a user to confirm their address, usually via a link or code, so if they enter the wrong address, no future emails are sent to that destination – but that doesn’t work as well when a user is providing an address they don’t control, such as sending emails to a third party via a service (like sending Xero invoices to a customer’s address). We wanted to make a single reusable microservice to store these bad emails, and allow our applications to check whether a user provided address was known to be bad, and if so provide feedback to the user.
Email might seem like a quaint relic in the days of $44B Twitter buyouts, but it’s still very relevant in modern business software, partly for communication, but also for things like automated notifications, third-party verifications, or inter-service connections. When the emails that your service sends out are critical – such as an urgent maintenance alert for a helicopter – it’s important to know whether the email address provided is usable, and you can’t necessarily wait for the 3rd party to verify they’ve received a message.
The Journey
With our destination in mind, we started looking into the world of Go, and found a rich ecosystem awaiting us. There was plenty of instructional material available online, with working examples and in-depth explanations of features and syntax, and in some cases full implementations of services to look at. After a brief tour of the language, we looked into working with databases, setting up web routes, and transforming data. After a few hours of this, we met to discuss which precise features we would need to implement in our microservice.
For our purposes, we didn’t need most of the components typically associated with web frameworks – there was no static content to deliver, no need for rendered templates or any frontend display, and our database layer was going to be very minimal, so no need for an especially thorough ORM. Out of the available frameworks, we decided to use Gin, a “Go framework that features a Martini-like API with performance that is up to 40 times faster” – which is a fancy way of saying it’s blazingly fast, minimalist, and modular. Sounds perfect for our use case, and when combined with MongoDB and Mongo Go Models for our database layer, we had all of the components we needed.
We identified our API structure, and the required capabilities of the service, and then set out to collaboratively create the router and its underlying logic. The Gin framework made this painless and quick, and by the end of our first day we had set up about 90% of our required features. We returned to the project a week later, and had deployed the first instance of our microservice by that afternoon. It’s been running smoothly since then, and we’ve been steadily integrating it with our existing applications as time allows. All in all, our foray into Go was a pleasant success. We’ve been looking at other use cases we could apply these skills into since then, and have found a few targets that we might tackle in future.
What we Loved
- Go is super integrated with tooling, such as the built in Go Modules tool for managing dependencies, or the excellent plugins for IDEs like VS Code.
- When they say Go is fast, they really mean it. It’s a very lightweight language – compilation is fast, binaries are small, and programs will run quickly.
- Go is statically typed – this ties in to the tooling integration, and means developing is predictable – even when using a 3rd party library, you can always trust that the values you get from a function will be what you expect.
- It’s very easy to learn – the numerous online tutorials are a big part of this, but more important is the inherent simplicity of the language. For a relatively low-level language, it has a very readable syntax; it’s similar to any other C-like language, so you can usually read a section of code and more or less understand it right away
- Despite being a low-level language, Go has dealt with a lot of the pain-points of modern development. Garbage collection is handled for you, it’s hard to break things with pointers, and, most impressively, concurrency is both expected and easy to work with via “goroutines” and channels.
What we Didn’t
- Go uses implicit interfaces – while this can make reuse and maintenance of code a bit easier, it can make it hard to tell if you’ve correctly implemented an interface without just trying to use it, which feels odd given how well the rest of the static analysis works.
- Errors in Go are handled quite differently from most other programming languages, being treated as a normal value rather than an exception. This isn’t necessarily a bad thing, but it adds a bit of adjustment time as you need to switch your thinking around errors.
Where can Go be used?
We’re enthusiastic about what Go can do, and excited to propose it to our clients where appropriate. That said, it’s definitely not a one-size-fits-all answer to the various problems we want to help our clients solve. If you’re thinking of working with us, we might recommend Go for your projects when:
- You want a lightweight, simple tool or service that needs to be easy to distribute
- You need a fast and concurrent solution, but don’t want to dedicate lots of resources just to getting your concurrency running
- You want to work with lower level concepts, but don’t want the headache of using C/C++
In particular, we think Go is great for lightweight microservice APIs, command-line utilities, background tasks, and for embedded systems.
14 December 2022 by Murray Tait
Part of being at the edge of tech innovation means ensuring everyone on the team is familiar with the full range of what your tech stack can achieve. In today’s episode, our adventurers – led by a software engineer with a knack for imaginative art projects – build a ground-up environment monitor using a very-low-power IoT microcontroller and sensor interface.
The goal of this project was to expand our development platform capabilities, and do some general hardware upskilling. We decided to create a weather station on an ESP32 microcontroller board with sensors that has the ability to send meaningful data from the device to the cloud via WIFI to be stored in a cloud-based data platform (yes, that’s code for “Google Sheets API” in this case – “as simple as possible but no simpler” is one of our favourite engineering principles).
A quick breakdown of the hardware we used:
- 1x ESP32 board
- 2x DHT11 temperature and humidity sensors
- 1x FC37 rain sensor
- 1x waterproof battery pack
We started by coding up some controller firmware using MicroPython, and flashed the ESP32 microcontroller with this. MicroPython is a great embedded development platform, using many of the same libraries as standard Python, and is very readable compared to alternative C-based microcontroller platforms. The two DHT11 temperature and humidity sensors were straightforward to use, as there is inbuilt support for this sensor in the standard MicroPython library.
We looked at two possible APIs for uploading the data to the cloud: AWS IoT, and Google Sheets. While AWS IoT would be a robust solution in a commercial product, we really wanted to focus on the hardware side of things, so we went with the simpler API, Google Sheets, opting to store the data in a cloud-based spreadsheet. This is an important strategy we commonly take when rapid prototyping – use the simplest thing that achieves our customers’ goals.
We then mounted the microcontroller along with the three sensors and LEDs on a breadboard for the prototyping phase, and connected the assembly to an IDE for quick development.
The main loop steps for collecting and sending data are:
- Wake up the board
- Connect to WiFi
- Register sensors and retrieve data
- Sign a json web token
- Send data to the cloud
- Receive a response
- Go to sleep for a configured period of time
After the prototyping phase was completed, we installed the device into a greenhouse, using a waterproof battery pack for power. One temperature/humidity sensor was placed inside the greenhouse, and one was placed outside along with the rain sensor, nearby a WiFi router for back-to-the-cloud connectivity. Once mounted, the device performed its main loop, sending through meaningful data to the Google sheet. We calibrated temperature results against a third portable thermostat to ensure we were collecting useful data.
Platform limitations
One of the limitations of using MicroPython is that there is currently a lack of driver support for some hardware made by Arduino. An example of this was a SPL06 barometer sensor that I was unable to get data from using MicroPython with the current available drivers. There are many ways we typically overcome these kinds of limitations in commercial products, from developing our own drivers (often in C), to finding other sensor options.
Next steps toward commercialisation
To progress a product like this toward commercialisation, we would start exploring with our customer how the product would be used in various real-world environments, and build up a set of design constraints from that.
This could include adding new features and sensors to the system, such as:
- Wind speed and direction
- Local storage for sensor data for retrieval by bluetooth
- Barometer
From here, the process would typically lead to a PCB board design phase, waterproof enclosure design, more robust calibration of the sensor array and hardening up the firmware communications protocols. Over time, this would progress to design-for-manufacture, adding more features, and growing the product from there.

23 November 2022 by Josiah Waldron
Emerj.js is a tiny library I wrote, inspired by, and to solve roughly the same core problem as, Facebook’s React, but leaving you to generate your HTML however you like best. I think React is pretty cool, but its size and JSX language is not to my taste. A stray comment on Hacker News got me thinking, and I figured out I could achieve React’s DOM diff/merge technique using builtin browser APIs to compare the live document tree with a fresh render, and update only the modified elements. The result is a flexible, light-weight tool to keep a live HTML user interface in sync with dynamically-changing data. Here’s how I got there.
Download
Emerj.js here on GitHub.
Web-based software has moved fast in five years, from mostly-static apps where the server sends an HTML page with a light seasoning of JavaScript (think the oldest versions of Hotmail), to fully client-side apps that render the entire HTML in the browser on the fly, and just pull raw data from a server via a web API (think modern Facebook).
The challenges of coding web UI have shifted considerably. In the old days, you’d pull some data from the database and populate this into an HTML template on the server side, and send this as an entire web page to the browser. You could make some amazing apps this way. And when your audience failed to be impressed, you would add some JavaScript to the page to do cool things like make a sidebar slide in when you clicked the menu icon.
When AJAX hit the streets, things got cooler. The user could push a button to add something to their shopping cart, and it would just zip into the cart without even reloading the page. You’d write some JavaScript to bump the number of items on the top-right, and the shopper would be so impressed they’d add a few more just to watch the number change before their eyes. Your code would look something like this:
<body>
<div class='num-in-cart'>0</div>
<ul class='cart'></ul>
<button name=add value='product-42'>+</button>
</body>
--
var num_in_cart = 0;
$('button[name=add]').on('click', function() {
var button = this;
$.ajax('/cart/add', function() {
num_in_cart++;
$('.num-in-cart').text(num_in_cart);
$('.cart').append('<li>'+button.value+'</li>');
})
})
That was great, and websites started to feel more like software and less like pages, and we started calling them “apps”.
The trouble is, this way of doing dynamic UIs doesn’t scale. Note how most of the update function is DOM manipulation and ad-hoc HTML construction. And this is an overly simplistic example—I’ve left out loads of important edge cases and usability niceties. You end up writing your HTML twice (once server-side and once to render updates), and that innocent-looking $('.num-in-cart').text() will explode into a thousand strings of spaghetti if you have anything remotely non-trivial about your data.
An elegant solution to this is to use a client-side template language, like Handlebars or Nunjucks (my favourite). Your code might look more like this:
<script type=text/template name='cart.html'>
<div class='num-in-cart'>{{ cart|length }}</div>
<ul>{% for item in cart %}<li>{{ item }}</li>{% endfor %}</ul>
<button name=add value='product-42'>+</button>
</script>
--
var data = {cart: []};
$('button[name=add]').on('click', function() {
$.ajax('/cart/add', function() {
data.cart.push(button.value);
dispatchEvent(new Event('data:updated'));
})
})
addEventListener('data:updated', function() {
var html = nunjucks.render('script[name="cart.html"]', data);
document.body.innerHTML = html;
})
dispatchEvent(new Event('data:updated'));
It’s a bit more code for this tiny example, but the code complexity scales exponentially better: you can have an arbitrarily complex a data structure, and as fancy a DOM as you like, and you only need to write your HTML once, cleanly, in a language much more suited to creating complex HTML than JavaScript is.
But wait.
This works ok. But we have a problem: every single element is replaced with an entirely new one, whether it’s changed or not. This is majorly problematic for two reasons:
- It performs badly. DOM rendering is among the slowest things a web browser does, so a full re-rerender on every update is bad. But it’s still waay faster than a page load, so this is a net win over server-side rendering.
- More importantly, you completely lose any element state. If the user had scrolled partway down a page, or typed some input, selected an option, or whatever, that disappears completely every time you re-render. Super annoying, and utterly non-functional.
You can avoid the second problem to an arbitrary extent by breaking your templates into smaller sub-templates and only updating portions of the page. But this also scales pretty badly, quickly becoming as crazy as the problem you’re trying to avoid.
The basic solutions
Rendering data seamlessly into your UI without a whole bunch of ad-hoc code, is (I believe) the basic problem that has driven the proliferation of frameworks and UI engines in the last few years, like Angular, React, and Ractive.js. It’s the trickiest part of writing a vanilla HTML/JavaScript UI. And some clever solutions have been uncovered.
Roughly speaking, they fall into these categories:
- Don’t bother. The web was never meant to work like this.
- DOM manipulation. So 2000s, with all problems as above.
- Use templating, and obliterate your document state every render.
- Use real HTML with extra semantic attributes to help bind your data directly to the live DOM, like plates.js or pure.js. All the above problems just take care of themselves. At first glance, this seems like the One True Way to do dynamic JavaScript UIs, because you’re using the tools of the web. But all avenues lead (very) quickly to suffering, as you can see from a quick scroll beyond the simplest examples in the plates README. Either your data model, your code, or your HTML will hurt.
- A component-aware system that selectively updates only changed elements, something like Angular and friends.
- A component-aware system that doesn’t bother keeping track of which components need updating. Just update them all, compare the resulting structure with the current live document, and only update the differences. This is what React and Ractive do, if I may oversimplify somewhat.
- Component-aware? Who needs it. Keep reading.
Reacting to the problem
Facebook’s React and the React-inspired Ractive.js are my picks for the best of the bunch. For one thing, they just focus on rendering UI. They’re libraries, not kitchen-sink frameworks, and I believe that’s a Good Thing.
The React folks hit on a great solution to the problem of replacing your entire DOM—instead of overwriting it, React renders to a “virtual DOM” and diffs it against the current virtual DOM, updating only those parts that differ. They describe how this works in their reconciliation algorithm.
To write the UI code in the first place, React provides a custom language called JSX, which I don’t particularly care for (it reminds me a lot of the bad old days before Unobtrusive JavaScript when we mixed PHP and JavaScript into our HTML with mad abandon). No, I don’t want to hear about how I can use native JavaScript instead of JSX if I want.
I like Ractive.js a bit better, but it still leaves me a little uninspired. I also maintain a lot of web UI code written in Jinja/Nunjucks, and it’s infeasible to just convert it all to Handlebars or JSX. I’d rather not be forced to make a choice of template language if I don’t have to.
The emerjent solution
And there’s the thing: I don’t have to. The concept can be made language-agnostic, by accepting anything that spits out a usable document tree. React itself probably could never be this, because they’re invested in their component architecture, but after realising it could be done, it wasn’t hard to implement. Every browser has an HTML parser built in, and this great virtual document model called … you guessed it … the DOM. If you create an element and don’t insert it into your document, then it’s virtual. Not real.
Let’s quickly get one myth out of the way: the DOM is not slow (you are). This is a common misperception, and one I believe was partly behind React’s choice to build their own. What’s behind the myth is that DOM rendering is slow. (and even that’s not slow, for what it does, if you’re careful).
But if your DOM root is not connected to the live document, then it’s super fast. Yes, you could build something faster with lightweight vanilla JavaScript objects, but, depending on your needs, likely not enough faster to be worth the effort.
So that’s pretty much how Emerj.js works. You render some HTML or build an out-of-document DOM however you like (Emerj doesn’t even need to know you exist at this stage), and then call Emerj’s single function to update your DOM. Here’s what the function does:
- Converts your HTML to a “virtual” DOM, if you haven’t already. This is easy:
var vdom = document.createElement('div');
vdom.innerHTML = html;
- Loops through the virtual DOM’s immediate children, and compares each one to the live DOM’s immediate child at the same position (or with the same ID).
- For each node, if it differs, updates it with fairly simple logic, mostly borrowed from React: if the tag name has changed, consider it a completely new element and replace it; if it’s a text node, update it if it differs; remove any missing attributes; add any new attributes; update any altered attributes
- Recurses into any children from step 2.
- Removes or adds any missing or extra children.
Your DOMs are now identical, and you’ve only modified the bare minimum.
Hey, you’re cheating!
“You’re cheating. React gives you a way to create HTML, composable components, etc, and Emerj just hands the problem off to a template language. That’s at least 50kb right there, and you haven’t really solved anything.”
Yeah. I’d like to quibble that React’s way of creating HTML isn’t all that exciting, and string concatenation doesn’t look too much worse than JSX. But I’m speaking from the sidelines: I’m not a React convert.
However, I’m not really trying to pitch Emerj as solving all the same problems that React solves. It doesn’t. React has loads more features out-of-the-box, is way more industry-tested, and provides a broader set of UI concepts and philosophies to build a UI around.
I’m also grateful to React for being a sensible solution to a single real problem in a world where everything else is a kitchen-sink framework.
Furthermore, Emerj wouldn’t exist without React. React is what triggered the idea to start with.
All I’m saying is, for me, and I hope others, Emerj addresses the basic problem that would drive me to React in the first place: updating an HTML UI from data on-the-fly, efficiently, without zapping document state, and without a whole bunch of nasty ad-hoc DOM manipulation. As for the rest of React, I’ve either found other solutions I’m happy with, or I’ve just never run into the problem that particular piece solves.
I’ve tested Emerj in the major browsers, and it performs really well for the job it does.
Specifically, the template in demo.html can be rendered more than 50 times per second in all browsers, on an ordinary modern laptop CPU, with all data fields updated each frame.
For another comparison, I implemented a (very) basic ToDo app in both React (todo-react.html) and Emerj (todo-emerj.html), and compared the times for adding items to the list in each:
| React | Emerj+Nunjucks | Emerj+Nunjucks
Using requestAnimationFrame to avoid stacking up unnecessary re-renders |
|---|
1500 items added
(full re-render each iteration): | 76s | 86s | 45s |
| 500 items: | 12.2s | 12.5s | 6.5s |
| 100 items: | 1.08s | 1.1s | 0.54s |
| 50 items: | 0.5s | 0.36s | 0.27s |
| 10 items: | 0.11 | 0.07s | 0.04s |
| 10 items added to a 10000-item list: | 6.7s | 8.9s | 3.3s |
(Please contact me if you see gaping holes in these comparisons, or get dramatically different results.)
In many scenarios, that’s quick enough to do animation with, though I don’t really recommend using Emerj for animation. CSS transitions are simpler and better, and direct DOM manipulation may be a better idea than trying to trick Emerj into animating an element by animating your data (a dubious idea at best).
As you can see, Emerj+Nunjucks (without requestAnimationFrame) is faster than React for small DOMs, but slows down somewhat for large DOMs. In actual fact, most of the time is spent parsing the resulting HTML into a DOM using .innerHTML. If you use a different, parse-free method of constructing a DOM tree, you could dramatically improve the speed on large complex documents.
Note the big gain from using requestAnimationFrame — clearly a good idea. The effect of using requestAnimationFrame is simply that the render code is not called more than once per frame. So of course this is faster: it’s doing less. Which is the only way to make code faster, anyway. I’m not sure whether React uses requestAnimationFrame internally (I would hope so, these days), so this column may not be apples-to-apples.
Again, the real advantage is not so much performance, but that state & identity of existing elements is preserved – text typed into an <input>, an open <select> dropdown, scroll position, ad-hoc attached events, canvas paint, etc, are preserved as long as an element remains, and that Emerj provides a simple way to make this happen. Never make your code more complicated to solve a performance problem you don’t have!
Shortfalls and improvements
There are a few minor pitfalls with this model, some of which React also has, but none of which are show-stoppers.
First, third-party or non-emerjent code that manipulates the on-page DOM will interfere with Emerj — any changes made will get overwritten in the next render. The ideal solution is to use Emerj for everything, but that’s not always feasible or even right. I plan to introduce two solutions for this, but need to spend time testing them in real life:
- an “emerj:ignore” attribute on the element, causing Emerj to skip updating the element, and
- an option to compare the virtual DOM with the previous virtual DOM, and only updating the live DOM where the two virtual DOMs differ.
Second, Emerj makes no attempt to solve the inverse problem: updating your data model when on-page widgets are changed (eg, the user types into an input field). Ractive does this. React does not. Kitchen-sink frameworks like Angular do. I believe it’s a separate, though admittedly closely-related, problem, that should be solved separately. And, if you use delegated events (if you’re not, you should be), the vanilla JavaScript way of doing it is not unpleasant.
Third, if you use Emerj with a template language (my preference), as opposed to some DOM-based component architecture (I don’t know any; do you?), the very minimum that needs to happen in a render is to parse the HTML into a DOM structure (and then loop through that DOM structure, but React must do this too). Hopefully .innerHTML is highly-optimised compiled C code, given it’s what web browsers do for a living, so it’s not terrible, but it’s certainly not free, either. React doesn’t have this problem, since it deals in objects, not text. Note this is not a limitation of Emerj as much as it is of whatever method you use to produce your DOM.
Fourth, there’s not much to help you with really complex components that have zillions of sub-elements or for some other reason are particularly slow to construct. React provides shouldComponentUpdate() for this purpose – if you know that a component doesn’t need to rerender, then save your cycles. However, Emerj has no way of doing this, because it doesn’t know anything about your components or DOM until after you’ve rendered. Emerj’s take on this is that it’s your problem. But there are relatively simple solutions. If you’re using a template library like Nunjucks, a simple cache-on-state tag might do the trick.
Fifth, my next reusable component will be an <ol> with English text for bullets. Seriously, React provides a pretty good attempt at a composable component architecture, something that, if you can figure out what those words mean, any good UI library should do. If you have a fancy date widget, but need one with a year selector, just subclass it. The sky’s the limit! Emerj doesn’t provide anything like this. That said, it also doesn’t need to: if you have a semi-decent way of producing HTML, part of that is bound to involve reusability in one form or another. My favourite, Nunjucks, has macros, which make for excellent reusable components. If you wanted, you could also do some pretty powerful things using native DOM instead rendering an HTML string.
Worthy mentions
Some good reads along these lines:
If you like the concept, then grab yourself a copy of Emerj here and start coding!
22 November 2017 by Bryan
2 comments
A review of Shop Class as Soulcraft by Matthew B. Crawford

It’s great to be a knowledge worker nerd in 2016. I mean that seriously — programmers continue to nurture the world’s greatest public library of information, programmer-mathematicians are modeling physical systems with ever-better realism, scientists are on the verge (since forever) of creating the first actually useful quantum computer, and Elon Musk is really going to send people to Mars in 2025.
And manual labour isn’t the only way to get stuff done anymore. Which means I don’t have to carry water to have a shower. I love not having to do that.
I love that coding is trendy nowadays — although there are downsides to having GitHub filled with every amateur’s half-finished prototype, on balance I think it’s more the kind of good that happens when craft beer gets crazy popular and you can find a rich dark ale without having to hunt down a quaint English pub far away in… England.
So when a philosopher/carpenter cousin of mine handed me a book pitched as “a philosopher/mechanic’s wise (and sometimes funny) look at the challenges and pleasures of working with one’s hands”, it struck enough cognitive dissonance in me to catch my nerdy interest.
Shop Class as Soulcraft by Matthew B. Crawford is a succinct critique of the modern knowledge economy, from someone who knows both sides of the fence pretty well. What caught my eye first was the surface similarity to a long-time favourite of mine, Zen and the Art of Motorcycle Maintenance (ZMM), which helped form some of my earliest articulate beliefs in the value of work done with care. “Shop Class“ is also written by a motorcycle mechanic, has a beautiful vintage motorbike pic on the front cover, and it turns out that Matthew Crawford is also a bit of a ZMM fan, quotes ZMM regularly, and discusses similar themes.
So I figured “Shop Class” would just be another one of those cheap knockoffs. And after skimming the first couple pages, I got suspicious that the book would be an overly-romanticised portrayal of the good old days, authenticity that’s so authentic you could vomit, and words like “craft“ and “artisan”, without really acknowledging either the dull reality of manual labour or the real rewards of intellectual labour.
It’s not. The book stands squarely on its own ground. It meshes well with ZMM, but where ZMM mainly philosophises (quite well) about “quality” and a view of the world that embraces both gestalt intuition and analytic reason, “Shop Class” lays out the concrete advantages of a specific way of life centered on manual work, and critiques knowledge work head-on.
It’s an engaging read, and worthwhile mindfood for the thoughtful programmer.
The book at a glance

Matthew Crawford’s basic premise is that, ever since “scientific management” and knowledge work became a thing, over the past 50-100 years, cerebral work has been put on a cultural pedestal, and manual labour has become an untouchable. His observation that shop class (“manual” here in New Zealand) has been elided from the American school curriculum is representative of this.
But, says Crawford, knowledge work isn’t all it’s cracked up to be, and is demoralising. It’s just so disconnected from the real ends that it achieves — you can dedicate a life career to, say, incentivising employee performance, barely ever meeting one of the folks who use the hedge trimmers that your company manufactures.
“Once the cognitive aspects of the job are located in a separate management class, or better yet in a process that, once designed, requires no ongoing judgment or deliberation, skilled workers can be replaced with unskilled workers at a lower rate of pay. … In the last thirty years American businesses have shifted their focus from the production of goods (now done elsewhere) to the projection of brands … Process becomes more important than product.”
This steers how we advise kids on their career choices (“You can do better than joinery. Get a science degree.”), and ultimately results in the degradation of both manual labour (it’s not good enough) and intellectual pursuit (skillful folks end up doing data entry under the name “business intelligence analyst”).
Crawford also bites hard at the tendency to absurdly and deceptively inflate job descriptions to make them seem less mundane. Modern teenagers don’t flip burgers, they are
“mavericks operating at the bohemian fringe … at the very heart of process innovation … in science and engineering, architecture and design
 [unleashing their people power] as they have fun while being the best. [A] small change made on the salesroom floor — by a teenage sales rep … acting on a thought to increase outreach. [O]ur economic success increasingly turns on harnessing the creative talents of each and every human being.
[unleashing their people power] as they have fun while being the best. [A] small change made on the salesroom floor — by a teenage sales rep … acting on a thought to increase outreach. [O]ur economic success increasingly turns on harnessing the creative talents of each and every human being.
Frank Levy, the MIT economist, responds to this by dryly noting that ‘where I live Best Buy seems to be starting people at about $8.00 an hour’.”
Crawford glows about the pleasures and benefits of manual work. The pride a builder takes in seeing his construction being used for its purpose in society, or the joy your electrician sparks when the lights go on. Touching more deeply, he notes the richness of being master of one’s own stuff (think the guy whose car company refuses to fix the engine, so, after a trip to the library for the car’s manual, starts messing around with it himself), and observes that manual interaction with the physical world is actually vital for clear thinking and philosophy about the real world.
“… in the practice of surgery, ‘dichotomies such as concrete versus abstract and technique versus reflection break down in practice. The surgeon’s judgment is simultaneously technical and deliberative, and that mix is the source of its power.’ The same could be said of any manual skill that is diagnostic, including motorcyle repair. You come up with an imagined train of causes for manifest symptoms and judge their likelihood before tearing anything down. This imagining relies on a stock mental library, … the functional kinds of an internal combustion engine, their various interpretations by different manufacturers, and their proclivities for failure.”
(Actually, that sounds a lot like debugging software.)
I like best that Crawford stands against the idea that 21st-century humans are smarter than ever before, and humanity is on the cusp of unlocking a complete internet-fueled brainpower revolution. He stresses that intellectual pursuit is hard, that creativity and smartness are the product of strenuous engagement with real-world constraints.
“The truth, of course, is that creativity is a by-product of mastery of the sort that is cultivated through long practice. It seems to be built up through submission (think a musician practicing scales, or Einstein learning tensor algebra). Identifying creativity with freedom harmonizes quite well with the culture of the new capitalism, in which the imperative of flexibility precludes dwelling in any task long enough to develop real competence.”
It’s not that modern tech is a bad thing, per se:
“Riding an early motorcyle entailed a certain preparation. … Set the choke … for the ambient temperature … Then approach the kick-starter with due apprehension, bracing yourself for yet another blow to your chronically bruised shin. Like a mule, [an early motorcycle] was emphatically not simply an extension of one’s will. Old bikes don’t flatter you, they educate you.”
It’s just that we’ve turned technology into a way to hide from, rather than engage with, reality. Technology exists for us, not the other way round, and the relative convenience of modern machines is great. But while we see it as freedom and control, it can also be a kind of imprisonment: we’re at the mercy of whoever designed the cheap plastic junk with magic smoke inside.
Where he’s heading with all this is that right from our school days, we’re pushed to view knowledge work as the desirable human endeavour, and manual labour as a fungible commodity, bothersome work that we receive “fair compensation” for — it doesn’t matter who (or what) stitches the shoes, or where. Our noble work as managers is to figure out how to make it all happen efficiently, but this disconnects us from what we produce and leaves us with little pride or sense of accomplishment in our work.
Worse, there is no direct accountability: if your toilet leaks after the plumber’s been through, you know who to call, and they’ll fix it for you, embarrassed they slipped up. But if worker efficiency drops, it’s much harder to point to the manager who implemented Party Fridays. Corporate language becomes empty, abstract, and morally ambiguous, like something from Orwell. And “teamwork” becomes more important than measurably good work.
Unlike manual work, the sausages that come out of the corporate machine are ambiguously defined, and their success or failure tends to be indirect. Being a team player becomes vital. Not treading on people’s toes is important. “Sensitivity training becomes necessary.” And the thing you’ll be measured on is your personality, your credentials, your prestige.
Not to mention your ability to use language to take others’ credit and hide direct blame. To quote a goodie:
“[O]ne of the principles of contemporary management is to ‘push details down and pull credit up.‘ That is, avoid making decisions [and] spin cover stories after the fact that interpret positive outcomes to your credit. … If things go well: ‘Finding cross-marketing synergies in the telecommunications and consumer electronics divisions has improved our strategic outlook heading into the fourth quarter.’ If things go badly: ‘Change the Vonage display? That was the kid’s idea. What’s his name, Bapu or something? Geez, these immigrants.’”
That’s terrible by anyone’s definition. So what’s the plan? Crawford sums it up pretty well in general terms:
“To live wakefully is to live in full awareness of this, our human situation. … Too often, the defenders of free markets forget that what we really want is free men. Conservatives are right to extol [private property] as a pillar of liberty, but when they put such arguments in the service of [corporate property], they become apologists for the ever-greater concentration of capital. The result is that opportunities for self-employment and self-reliance are preempted by distant forces.
[It] seems best to conclude by registering a note of sobriety. [Despair or a fantasy of futuristic revolution] distract from the smaller but harder work of living well in this life. The alternative to revolution … is resolutely this-worldly. … In practice, this means seeking out the cracks where individual agency and the love of knowledge can be realized today, in one’s own life.”
Despair, revolution, and this-worldliness for nerds

At first glance, this isn’t what a professional programmer wants to hear. Why am I bothering?
Firstly, the book is a healthy critique of much that’s wrong with the professional world of software development, and if programmers don’t engage with it, then we’ll just stay in our echo chamber.
There’s a lot that I can identify with in the Crawford’s dim view of corporate culture, and nerds aren’t exempt. And while I don’t actually think, like some world-weary programmers, that programming sucks, there are a couple dark sides to the work that can suck your soul.
We programmers dream in abstractions, and it’s a daily challenge to keep both feet on the ground. Programmers get drawn to rockstar abstractions, perhaps because the alternative — like a movie star hanging out laundry — just seems too mundane. An AI system to cluster documents when a simple text search would do. A peer-to-peer network architecture when all you need is a pipe. XSLT. Enough said.
It’s also sometimes difficult just to get things done in software, because there are so many generic methodologies and processologies — manual labour doesn’t have a monopoly on mundane tasks. 100-page specs, all detail and no clarity, or 300-page ISO standards that say next to nothing — those guys haven’t read their William Zinsser. These processes rarely catch the kinds of things that can make or break a feature, the things that come out when a real human sits behind the first half-working prototype.
Programmers also get easily hooked on a given method(ology) as the one true way. If we’ve been burnt in the past by forgetting whether a variable was milliseconds or seconds or average donuts per american male, we start prefixing every variable name with ms_ or donuts_ or taintedB64String_. This kind of code tic quickly balloons and makes for incomprehensible code. “Does this 20-line if statement actually do anything, or is it all because some coder had a rule that every function call had to be wrapped in a failure-catching block?”
These crazy things are normal because software quality is so hard to measure. If you’re after a completely objective measuring-stick, “it works” is about as objective as it gets for software, and even that’s often ambiguous. But what works today may break tomorrow, because a developer failed to communicate her intent clearly. Functional correctness is not a very good measure of what matters — with software, perhaps more so than anything else besides the creative arts, the real quality judgment is in the feel of the thing, the aesthetic value of what lies beneath, the intentions of the author.
Meaning and comprehensibility are all-important factors in software development, unlike, say, plumbing, and for good reason: software has a presence far beyond its immediate function. It is honed and maintained by humans, and if humans don’t get or like it, then it dies.
So Crawford’s criticism comes full circle: a machine that you don’t understand, owns you, not the other way around, and this is why the true measure for the quality of software is not simply whether it works, but how lucidly it sings.
Secondly, what I found coolest about Crawford’s vivid account of his work repairing motorcycles for their enthusiast owners, was not the contrast to knowledge work, but the number of striking similarities to the average day in the life of a programmer.
Crawford spends a bit of time on the cognitive value of manual work. Someone who works with their hands engages the physical world in ways that theoretical scientists only theorise about. This means they grow to truly understand its behaviours and quirks, and this enables them to reason about the world and solve problems and create theories that mesh well with the physical world.
“Many inventions capture a reflective moment in which some worker has made explicit the assumptions that are implicit in his skill. … The steam engine is a good example. It was developed by mechanics who observed the relations between volume, pressure, and temperature … at a time when theoretical scientists were tied to the caloric theory of heat, [which turned out to be a dead end].“
He also discusses the unique character of repair work:
“There is always a risk of introducing new complications when working on decrepit machines, and this enters the diagnostic logic. Measured in likelihood of screwups, the cost is not identical for all avenues of inquiry when deciding which hypothesis to pursue — for example, when trying to figure out why a bike won’t start. … Do you really want to check the condition of the starter clutch, if each of the eight screws will need to be drilled out?”
He’s debugging the bike. Fixing bugs is not the most fun part of programming, to be sure, but it’s the most character-building. The part where you learn not to make wild assumptions. The part where you grow up and start taking responsibility for your mistakes and being careful not to break something that somebody else thought hard about.
Programmers make machines do stuff. We carefully fit pieces of machinery together (never mind for now that the pieces are often abstractions), constrained by rules as unbending as the laws of physics that constrain a mechanic filing a valve to fit a valve chamber. We make judgement calls about the health of a system by listening to the funny noises it makes when the fluid drips from the leaks. We dismantle these pieces of machinery until we find what piece is skewing the timing. Or we find that the problem was in a different place of the system entirely, and, huffing, we piece it all back together again.
We make parts for the machine that cause other parts to move, shuffle, turn, which in turn causes yet more parts to tumble, vibrate, fire, so that ultimately the machine fills its born purpose, if we do our job well.
I’m not trying to be down on abstractions. The cool thing is that abstractions are part of this machinery. They’re part of what makes a coder’s job different from other engineering. Without abstractions, computers would be more-or-less useless in the modern world. The difficulty is getting them right.
As programmers, we can’t assume just because abstractions are vital to our craft, that we must use them whenever possible. The opposite is true. Abstractions are like advice from a friend: in measured doses, life-giving, but in large quantities or at the wrong time, just hot air.
Open Source: possess by understanding
 Richard Stallman, Open Source prophet guy
Richard Stallman, Open Source prophet guy
One of Crawford’s complaints is how you can’t just open up the hood of a car nowadays and fix the problem yourself; you need hi-tech diagnostic tools that at best give you an error code to look up in a manual, but no actual insight into the problem.
My father-in-law often makes this same complaint, and it’d be easy to dismiss it as technophobia. But it’s not, actually — it’s a healthy desire to be “master of one’s own stuff”. It’s a real problem with hi-tech machinery and software.
According to Goethe, “What we do not understand, we do not possess.”
This is the real drive behind the open-source software movement. I make my living writing proprietary software, but I’m profoundly aware that I depend for my living on open-source software. The availability and quality of open-source software is one reason (sometimes arguable), but the fact that it’s open and hackable is vital to a library becoming an integral part of a project that will live for ten years or more.
Closed-source software, like all the incomprehensible machines and theories that history’s forgotten, will lose out in the very long run, and open-source software will replace it — as evidenced by all the hacker-friendly projects that have taken off on Kickstarter in the last few years.
Some Criticism
Crawford’s points aren’t always spot on. There is a touch of romanticism there. He preaches that knowledge work is a losing proposition for most career-seekers, unless they really loved academia, largely on the basis of his belief that the need for manual labour isn’t decreasing — we will always need people to build houses, fix plumbing, and raise cattle.
True, but he takes it a bit far, partly due to what seems to be naiveté on his part. While he does acknowledge that industrialism’s happened, and the assembly line and all that, he doesn’t seem to be aware of the direction that smart robots, industrial automation, and clever building materials are heading, fast. He talks about AI as if it’s not dramatically different from a clever counting machine — and he’s half-right, but missing the point.
Not this year or next year, but in the next 20 years (when my kids will be starting their careers), his advice against knowledge work will be bad advice for most people, if it isn’t already.
(By that time, the Mars colonies will be needing farmers, of course. But they’ll be farmers with physics degrees. Or Matt Damon.)
Is there a future for manual labour in a postindustrial world? Is it gone for good or as vital as ever? Is technology on an exponential path to utopia, or is that a technocrat dreamer’s vision, ignoring the fact that technology’s only possible because we’ve raped the natural and human resources of societies less fortunate? Are programmers susceptible to unhealthy patterns that traditional jobs are not?
1 November 2016 by Bryan
What’s an HTTP API?

Good question. “API” stands for Application Programming Interface. In general, it’s a way for programmers to connect their software to an existing piece of software or hardware.
When hearing the term “API” many people think of a particular kind of API, but in reality the term covers just about any kind of software interconnection. Graphics programming libraries, database access, browser extensions, news and weather feeds, and so on — these are all APIs in one form or another.
HTTP APIs (or web APIs) let your software retrieve and modify information on a web server. For example:
- Adding an item to your online shopping cart.
- Refining search results without the need to completely reload a page.
- Sending travel information between websites
- Getting information for a graph.
- Loading select social media posts on your sports club’s website.
- Displaying auction listings from the likes of trademe on your website.
Choices to make up front
There’s not just one kind of web API. You have browser APIs to interact with and control a web browser, modify its display or behaviour using JavaScript or a plugin architecture. Then you have server APIs, which typically allow a third-party developer to work with information stored on a remote server, sometimes from web browsers, sometimes from another server, sometimes from another bit of software.
I’ll be talking specifically about server APIs via HTTP. There are a lot of commonly-used technologies: REST, SOAP, JSON, RPC, XML. They all have various pros and cons, but I’ll use Python, Flask (a popular microframework for Python), REST and JSON to demonstrate the concepts.
Setting up your API
Assuming you have Flask installed already, here’s a simple single-file website that works:
from random import randint
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/api/hello")
@app.route("/api/hello/<int:max_num>")
def hello(max_num=10):
""" Return a Hello World message along with a random number """
return jsonify(message="Hello World!", number=randint(1, max_num))
if __name__ == "__main__":
app.run()
Some tutorials for other laguages:
Building a great API
URL structure
To make life easier for anyone using your API, you’ll need a good URL structure. This will make your API easier to work with, and save users a lot of time.
- Try to keep your URL format consistent across different API calls/endpoints.
- Include an API version number if you think you may need to rework your API at some stage.
- Decide whether or not you want to support (or enforce use of) https.
For example:
http[s]://apiv1.example.com/product-categories/
http[s]://apiv1.example.com/product-categories/3487/
http[s]://apiv1.example.com/product-categories/3487/specials/
Or
http[s]://api.example.com/v1/product-categories/
Data & response structure
Next you should have a sensible, consistent data structure. How exactly you structure your response depends on your requirements, but it should return useful information, and an appropriate HTTP status code. Common status codes would be 200 for a successful request, 403 for request denied (eg. invalid credentials), 404 for resource not found and 500 for a server error.
A basic message-only response:
{ "message": "Purchase OK" }
A bad message-only response:
{ { "status": {"message": "Purchase OK" } }
What’s bad about this? There is a superfluous layer of nesting, and needless extra keys.
A message containing a list of shopping basket items:
{ "items": [ { "id": 123, "description": "Parcel tape", "quantity": 1 },
{ "id": 456, "description": "Wrapping paper", "quantity": 1 },
{ "id": 789, "description": "Label", "quantity": 3 } ] }
Similarly, you could do things very wrong:
{ "ids": [123, 456, 789],
"descriptions": ["Parcel tape", "Wrapping paper", "Label"],
"quantities": [1, 1, 3] }
While it might look like we avoided the needless use of keys and made our data structure tidy and compact, it’s much harder to guarantee that the shopping basket ids, descriptions and quantities have been added in the correct order.
Try to make your data structures sensible, consistent, and readable to the human eye. Group related information information together.
It’s also worth making your response structures consistent across different API endpoints — for example, avoid calling a message “message” in one endpoint, “response” in the next, “note” in another.
Error handling
This is another essential. When there is an error, you need to make sure that your API handles it gracefully, and informs anyone who needs to know about it. A typical approach is to issue an error message in your JSON response in conjunction with an appropriate HTTP status code.
If it’s a serious error that’s not the API user’s fault, it’s also a good idea to send an email to your development team both advising of, and describing, the error so they can fix the fault. Include the exception name and a stack trace at a minimum. Depending on your requirements, you might also want to log it to disk.
Python’s logging module (version 2 | 3) is great for handling this.
Authentication and Access Control.
Depending on what you’re doing, this may or may not be necessary. For a public API, you probably don’t need to worry about it. If you’re using a local web server on a locked-down embedded device, it’s probably not an issue. But if you want to limit your audience or the volume of requests, you’ll need some way to restrict and allow access.
There are several common methods for doing authentication. It’s often a tradeoff between security and convenience. Weigh up how sensitive your API’s information is. If it’s financial information you’ll want it pretty tight, but if it’s a small list of products which can be viewed by the public anyway then it won’t be such a pressing concern.
One easy & simple way is to include an API username and key in the request URL, and check this against a known list. For example:
https://apiv1.website.domain/member/123/details?user=bob&key=P1neapple
When a request is made to this URL you’d compare the user (bob) and key (P1neapple) to a list of allowed key/user combinations, and then compose an appropriate JSON response, or an HTTP 403 if they’re not allowed in. You could also omit the username entirely and simply use a long and unique key for each API user.
While easy and convenient, this method is not very secure as your user credentials will be stored in any place which logs the request URL. You should never use URL-based authentication when transferring sensitive information.
To make authentication more secure you could place API credentials in the request header, or use OAuth.
Some annoying things to avoid
Simplistic credential management: An entry in a settings file is fine if you only have one or two users but if you’re supporting quite a few then it could get unwieldy very quickly. Consider storing API credentials in a database to make managing access for multiple users easier in the long run.
No documentation: Make sure you have some. Besides making life easier for anyone who uses your API, its presence shows that you’ve put a lot of thought and effort into your API. Your target audience is developers who use your API, but remember they’re humans first. Keep your documentation simple and to the point.
User experience & needless requests: Your API users are likely to be developers, but they’re still users. Consider how they might expect to use it. Is there a sensible way you can provide all the information they’re likely to need without needing to issue multiple requests?
Sluggishness: If you’re returning lots of information speed can be an issue. This can come from any number of areas and you’ll need to run the appropriate benchmarks and tests, but in most data-heavy APIs you should look hard at your database queries – return only the columns/fields you need and make good use of JOINs. If you’re using django (another Python framework), learn to love .select_related() and .prefetch_related()!
Any kind of API is a user interface for programmers. Even though it’s graphical, basic UI principles still apply: clarity, consistency, visibility, feedback, avoiding surprising behaviour, and a sensible mapping between what the user sees and what happens under the hood. Remember that the end-users are human, and you’re on the right track.
16 September 2016 by andrew
 Cool. We’re finalists for the second year in a row. Our satellite-based bee monitor is an agri-tech innovation for beekeepers called Hivemind.
Cool. We’re finalists for the second year in a row. Our satellite-based bee monitor is an agri-tech innovation for beekeepers called Hivemind.
14 June 2016 by Berwyn
 I love new technologies that might benefit people’s products. We’ve supported development on these three nifty platforms:
I love new technologies that might benefit people’s products. We’ve supported development on these three nifty platforms:
- MicroPython, a platform for rapid development of IoT. We’re now using this for customerproducts.
- The LoPy, a low-cost LoRa module that can communicate several kilometers between sensors just operating on batteres using unlicensed RF bands. Also powered by MicroPython rapid development.
- ESP8266, a nano-cost WiFi module, also powered by MicroPython rapid development.
Other reasonably-priced technologies that we’re keeping our eye on are:
- Centimeter-accurate positioning of people or equipment.
- Technology for nanosecond-resolution timing between sensor nodes.
- Bio-sensors and other sensors for IoT products.
- Low-cost satellite technology for remote operations.
14 June 2016 by Berwyn

“If you can’t measure it, you can’t improve it” says Peter Drucker’s adage. IoT for business is not just cool tech. It’s measuring what you need to know: whether it’s agriculture, bio sensing, or supply chain. “Internet of Things” (IoT) is a fairly new buzzword, but as a company it’s nothing new: we’ve been working in this field for 10 years.
Does your business need to measure asset location, bee hive health, customer location within your store, the health of your patient, or keep track of your factory process? You may even need us to make an app to present that data helpfully. Let us know.
In summary, measuring things is becoming a whole lot easier. Think through your business. The chances are high that you can benefit from IoT for business.
14 June 2016 by Berwyn
 Okay, so here’s a little rant (by a fellow developer) about web forms that accept credit card numbers. Or rather, web forms that don’t accept them very well.
Okay, so here’s a little rant (by a fellow developer) about web forms that accept credit card numbers. Or rather, web forms that don’t accept them very well.
Many card number input boxes are limited to 16 characters, meaning when I get up to “1234 5678 1234 5” and then try to type the last three digits … BANG, input box full, no more typie. I have to go back and delete the spaces, making it harder to read and check. I had this just today when paying for my Highrise account (though I’m not really picking on 37signals — it happens on many payment sites).
The other one that I get fairly often is when a site lets me enter the number with spaces, but then the server-side check comes back and says “invalid credit card number”. Um, no it’s not invalid — I’m typing it exactly as it appears on my card.
C’mon, folks, we’re programmers! Stripping out non-digits is the kind of thing computers can do in nano- or micro-seconds. What exactly is so hard about adding one line of code?
card_number = ''.join(c for c in card_number if c.isdigit())
If you’re taking money that I want to give you, please at least let me enter my card number as it appears on my card — digit groups separated by spaces. Stripping really isn’t that hard! :-)
12 July 2013 by Ben
28 comments

My wife gave me a real geek book for Christmas: Masterminds of Programming by two guys named Federico Biancuzzi and Shane Warden. In it they interview the creators of 17 well-known or historically important programming languages.
Overview
The book was a very good read, partly because not all the questions were about the languages themselves. The interviewers seemed very knowledgeable, and were able to spring-board from discussing the details of a language to talking about other software concepts that were important to its creator. Like software engineering practices, computer science education, software bloat, debugging, etc.
The languages that everyone’s heard of and used are of course in there: C++, Java, C#, Python, Objective-C, Perl, and BASIC. There are a few missing — for example, the Japanese creator of Ruby didn’t feel comfortable being interviewed in English, and the publishers considered translation too expensive.
But what I really liked were interviews about some of the domain-specific languages, such as SQL, AWK, and PostScript. As well as some of the languages that were further off the beaten track, like APL, Haskell, ML, Eiffel, Lua, and Forth. The one thing I didn’t go for was the 60 pages with the UML folks. That could have been cut, or at least condensed — half of it (somewhat ironically) was them talking about how UML had gotten too big.
If you’re a programmer, definitely go and buy the book (the authors paid me 0x0000 to say that). But in the meantime, below are a few more specific notes and quotes from the individual interviews.
This review got rather long. From here on, it’s less of a real review, and more my “quotes and notes” on the individual chapters. I hope you’ll find it interesting, but for best results, click to go to the languages you’re interested in: C++, Python, APL, Forth, BASIC, AWK, Lua, Haskell, ML, SQL, Objective-C, Java, C#, UML, Perl, PostScript, Eiffel.
C++, Bjarne Stroustrup
C++ might be one of the least exciting languages on the planet, but the interview wasn’t too bad.
I knew RAII was big in C++, and Stroustrup plugged it two or three times in this fairly short interview. Another thing I found interesting was his comment that “C++ is not and was never meant to be just an object-oriented programming language … the idea was and is to support multiple programming styles”. Stroustrup’s very big on generic programming with templates, and he badgered Java and C# for adding generics so late in their respective games.
He does note that “the successes at community building around C++ have been too few and too limited, given the size of the community … why hasn’t there been a central repository for C++ libraries since 1986 or so?” A very good thought for budding language designers today. A PyPI or a CPAN for C++ would have been a very good idea.
As usual, though, he sees C++ a little too much as the solution for everything (for example, “I have never seen a program that could be written better in C than in C++”). I think in the long run this works against him.
Python, Guido van Rossum
One thing Python’s creator talks about is how folks are always asking to add new features to the languages, but to avoid it becoming a huge hodge-podge, you’ve got to do an awful lot of pushing back. “Telling people you can already do that and here is how is a first line of defense,” he says, going on to describe stages two, three, and four before he considers a feature worth including into the core. In fact, this is something that came up many times in the book. To keep things sane and simple, you’ve got to stick to your vision, and say no a lot.
Relatedly, Guido notes, “If a user [rather than a Python developer] proposes a new feature, it is rarely a success, since without a thorough understanding of the implementation (and of language design and implementation in general) it is nearly impossible to properly propose a new feature. We like to ask users to explain their problems without having a specific solution in mind, and then the developers will propose solutions and discuss the merits of different alternatives with the users.”
After just reading Stroustrup’s fairly involved approach to testing, Guido’s approach seemed almost primitive — though much more in line with Python’s philosophy, I think: “When writing your basic pure algorithmic code, unit tests are usually great, but when writing code that is highly interactive or interfaces to legacy APIs, I often end up doing a lot of manual testing, assisted by command-line history in the shell or page-reload in the browser.” I know the feeling — when developing a web app, you usually don’t have the luxury of building full-fledged testing systems.
One piece of great advice is that early on when you only have a few users, fix things drastically as soon as you notice a problem. He relates an anecdote about Make: “Stuart Feldman, the original author of “Make” in Unix v7, was asked to change the dependence of the Makefile syntax on hard tab characters. His response was something along the lines that he agreed tab was a problem, but that it was too late to fix since there were already a dozen or so users.”
APL, Adin Falkoff
APL is almost certainly the strangest-looking real language you’ll come across. It uses lots of mathematical symbols instead of ASCII-based keywords, partly for conciseness, partly to make it more in line with maths usage. For example, here’s a one-liner implementation of the Game of Life in APL:

Yes, Falkoff admits, it takes a while to get the hang of the notation. The weird thing is, this is in 1964, years before Unicode, and originally you had to program APL using a special keyboard.
Anyway, despite that, it’s a very interesting language in that it’s array-oriented. So when parallel computing and Single Instruction, Multiple Data came along, APL folks updated their compilers, and all existing APL programs were magically faster without any tweaking. Try that with C’s semantics.
Forth, Chuck Moore
Forth is a small and very nifty language that holds a special place in my heart. :-) It’s quirky and minimalistic, though, and so is it’s creator.
He’s an extremist, but also sometimes half right. For example, “Operating systems are dauntingly complex and totally unnecessary. It’s a brilliant thing Bill Gates has done in selling the world on the notion of operating systems. It’s probably the greatest con the world has ever seen.” And further on, “Compilers are probably the worst code ever written. They are written by someone who has never written a compiler before and will never do so again.”
Despite the extremism in the quotes above, there’s a lot folks could learn from Forth’s KISS approach, and a lot of good insight Moore has to share.
BASIC, Tom Kurtz
I felt the BASIC interview wasn’t the greatest. Sometimes it seemed Kurtz didn’t really know what he was talking about, for instance this paragraph, “I found Visual Basic relatively easy to use. I doubt that anyone outside of Microsoft would define VB as an object-oriented language. As a matter of fact, True BASIC is just as much object-oriented as VB, perhaps more so. True BASIC included modules, which are collections of subroutines and data; they provide the single most important feature of OOP, namely data encapsulation.” Modules are great, but OO? What about instantiation?
Some of his anecdotes about the constraints implementing the original Dartmouth BASIC were interesting, though: “The language was deliberately made simple for the first go-round so that a single-pass parsing was possible. It other words, variable names are very limited. A letter or a letter followed by a digit, and array names, one- and two-dimensional arrays were always single letters followed by a left parenthesis. The parsing was trivial. There was no table lookup and furthermore, what we did was to adopt a simple strategy that a single letter followed by a digit, gives you what, 26 times 11 variable names. We preallocated space, fixed space for the locations for the values of those variables, if and when they had values.”
AWK, Al Aho, Brian Kernighan, and Peter Weinberger
I guess AWK was popular a little before my (scripting) time, but it’s definitely a language with a neat little philosophy: make text processing simple and concise. The three creators are honest about some of the design trade-offs they made early on that might not have been the best. For example, there was tension between keeping AWK a text processing language, and adding more and more general-purpose programming features.
Apparently Aho didn’t write the most readable code, saying, “Brian Kernighan once took a look at the pattern-matching module that I had written and his only addition to that module was putting a comment in ancient Italian: ‘abandon all hope, ye who enter here’. As a consequence … I was the one that always had to make the bug fixes to that module.”
Another interesting Aho quote, this time about hardware: “Software does become more useful as hardware improves, but it also becomes more complex — I don’t know which side is winning.”
This Kernighan comment on bloated software designs echoes what Chuck Moore said about OSs: “Modern operating systems certainly have this problem; it seems to take longer and longer for my machines to boot, even though, thanks to Moore’s Law, they are noticeably faster than the previous ones. All that software is slowing me down.”
I agree with Weinberger that text files are underrated: “Text files are a big win. It requires no special tools to look at them, and all those Unix commands are there to help. If that’s not enough, it’s easy to transform them and load them into some other program. They are a universal type of input to all sorts of software. Further, they are independent of CPU byte order.”
There’s a lot more these three say about computer science education (being educators themselves), programming vs mathematics, and the like. But you’ll have to read the book.
Lua, Roberto Ierosalimschy and Luiz Henrique de Figueiredo
Lua fascinates me: a modern, garbage-collected and dynamically typed scripting languages that fits in about 200KB. Not to mention the minimalist design, with “tables” being Lua’s only container data type. Oh, and the interview was very good too. :-)
As an embedded programmer, I was fascinated by a comment of Roberto’s — he mentions Lua’s use of C doubles as the single numeric type in Lua, but “even using double is not a reasonable choice for embedded systems, so we can compiler the interpreter with an alternative numerical type, such as long.”
Speaking of concurrency, he notes that in the HOPL paper about the evolution of Lua they wrote, “We still think that no one can write correct programs in a language where a=a+1 is not deterministic.” I’ve been bitten by multi-threading woes several times, and that’s a great way to put!
They note they “made many small [mistakes] along the way.” But in contrast to Make’s hard tab issue, “we had the chance to correct them as Lua evolved. Of course this annoyed some users, because of the incompatibilities between versions, but now Lua is quite stable.”
Roberto also had a fairly extreme, but very thought provoking quote on comments: “I usually consider that if something needs comments, it is not well written. For me, a comment is almost a note like ‘I should try to rewrite this code later.’ I think clear code is much more readable than commented code.”
I really like these guys’ “keep it as simple as possible, but no simpler” philosophy. Most languages (C++, Java, C#, Python) just keep on adding features and features. But to Lua they’ve now “added if not all, most of the features we wanted.” Reminds me of Knuth’s TeX only allowing bugfixes now, and its version number converging to pi — there’s a point at which the feature set just needs to be frozen.
Haskell, Simon Peyton Jones, John Hughes, and Paul Hudak
I’ve heard a lot about Haskell, of course, but mainly I’ve thought, “this is trendy, it must be a waste of time.” And maybe there’s truth to that, but this interview really made me want to learn it. John’s comments about file I/O made me wonder how one does I/O in a purely functional language…
It’s a fascinating language, and if Wikipedia is anything to go by, it’s influenced a boatload of other languages and language features. List comprehensions (and their lazy equivalent, generator expressions), which are one of my favourite features of Python, were not exactly invented by Haskell, but were certainly popularized by it.
There’s a lot more in this interview (on formalism in language specification, education, etc), but again, I’m afraid you’ll have to read the book.
ML, Robin Milner
Sorry ML, I know you came first in history, but Haskell came before you in this book, so you were much less interesting. Seriously though, although ML looks like an interesting language, this chapter didn’t grab me too much. There was a lot of discussion on formalism, models, and theoretical stuff (which aren’t really my cup of tea).
What was interesting (and maybe this is why all the formalism) is that ML was designed “for theorem proving. It turned out that theorem proving was such a demanding sort of task that [ML] became a general-purpose language.”
SQL, Don Chamberlin
One often forgets how old SQL is: almost 40 years now. But still incredibly useful, and — despite the NoSQL people — used by most large-scale websites as well as much desktop and enterprise software. So the interview’s discussion of the history of SQL was a good read.
One of the interesting things was they wanted SQL to be used by users, not just developers. “Computer, query this and that table for X, Y, and Z please.” That didn’t quite work out, of course, and SQL is really only used by developers (and with ORMs and suchlike, much of that is not hand-coded). But it was a laudable goal.
The other interesting point was the reasons they wanted SQL to be declarative, rather than procedural. One of the main reasons was optimizability: “If the user tells the system in detailed steps what algorithm to use to process a query, the the optimizer has no flexibility to make changes, like choosing an alternative access path or choosing a better join order. A declarative language is much more optimizer-friendly than a lower-level procedural language.” Many of the other database query languages of the day were more procedural, and nobody’s heard of them today.
Objective-C, Tom Love and Brad Cox
When I started writing Oyster.com’s iPad app, I of course had to learn Objective-C. At first (like most developers) I was put off by [all [the [square brackets]]] and the longNamesThatTryToDocumentThemselves. But after you get into it, you realize that’s just syntax and style, and the core of Objective-C is actually quite elegant — adding Smalltalk-style OO to C in a low-impact way.
It’s been popularized by Apple for Mac and iOS development, of course, and also been expanded heavily by them, but it really hasn’t strayed from its roots. As Tom Love said, it’s “still Objective-C through and through. It stays alive.”
Tom gives some reasoning behind the ugly syntax: “The square brackets are an indication of a message sent in Objective-C. The original idea was that once you built up a set of libraries of classes, then you’re going to spend most of your time actually operating inside the square brackets … It was a deliberate decision to design a language that essentially had two levels — once you had built up enough capability, you could operate at the higher level … Had we chosen a very C-like syntax, I’m not sure anybody would know the name of the language anymore and it wouldn’t likely still be in use anywhere.”
Tom Love has gone on to be involved with some huge systems and codebases (millions of lines of code), and shares some experience and war stories about those. One of the more off-the-wall ideas he mentions to help would-be project managers get experience is to have a “project simulator” (like a flight simulator): “There is a problem of being able to live long enough to do 100 projects, but if you could simulate some of the decisions and experiences so that you could build your resume based on simulated projects as contrasted to real projects, that would also be another way to solve the problem.”
When asked, “Why emulate Smalltalk?”, Brad Cox says that “it hit me as an epiphany over all of 15 minutes. Like a load of bricks. What had annoyed me so much about trying to build large projects in C was no encapsulation anywhere…”
Comparing Objective-C to C++, he pulls out an integrated circuit metaphor, “Bjarne [C++] was targeting an ambitious language: a complex software fabrication line with an emphasis on gate-level fabrication. I was targeting something much simpler: a software soldering iron capable of assembling software ICs fabricated in plain C.”
One extreme idea (to me) that Brad mentions is in his discussion of why Objective-C forbids multiple inheritance. “The historical reason is that Objective-C was a direct descendant of Smalltalk, which doesn’t support inheritance, either. If I revisited that decision today, I might even go so far as to remove single inheritance as well. Inheritance just isn’t all that important. Encapsulation is OOP’s lasting contribution.”
Unfortunately for me, the rest of the interview was fairly boring, as Brad is interested in all the things I’m not — putting together large business systems with SOA, JBI, SCA, and other TLAs. I’m sure there are real problems those things are trying to solve, but the higher and higher levels of abstraction just put me to sleep.
Java, James Gosling
Like the C++ interview, the Java interview was a lot more interesting than the language is.
I know that in theory JIT compilers can do a better job than more static compilers: “When HotSpot runs, it knows exactly what chipset you’re running on. It knows exactly how the cache works. It knows exactly how the memory hierarchy works. It knows exactly how all the pipeline interlocks work in the CPU … It optimizes for precisely what machine you’re running on. Then the other half of it is that it actually sees the application as it’s running. It’s able to have statistics that know which things are important. It’s able to inline things that a C compiler could never do.” Those are cool concepts, but I was left wondering: how well do they actually work in practice? For what cases does well-written Java actually run faster than well-written C? (One might choose Java for many other reasons than performance, of course.)
James obviously has a few hard feelings towards C#: “C# basically took everything, although they oddly decided to take away the security and reliability stuff by adding all these sort of unsafe pointers, which strikes me as grotesquely stupid.”
And, interestingly, he has almost opposite views on documentation to Roberto Ierosalimschy from Lua: “The more, the better.” That’s a bit of a stretch — small is beautiful, and there’s a reason people like the conciseness of K&R.
C#, Anders Hejlsberg
Gosling may be right that C# is very similar to (and something of a copy of) Java, but it’s also a much cleaner language in many ways. Different enough to be a separate language? I don’t know, but now C# and Java have diverged enough to consider them quite separately. Besides, all languages are influenced by existing languages to a lesser or greater extent, so why fuss?
In any case, Anders was the guy behind the Turbo Pascal compiler, which was a really fast IDE and compiler back in the 1980’s. That alone makes him worth listening to, in my opinion.
What he said about the design of LINQ with regard to C# language features was thought-provoking: “If you break down the work we did with LINQ, it’s actually about six or seven language features like extension methods and lambdas and type inference and so forth. You can then put them together and create a new kind of API. In particular, you can create these query engines implemented as APIs if you will, but the language features themselves are quite useful for all sorts of other things. People are using extension methods for all sorts of other interesting stuff. Local variable type inference is a very nice feature to have, and so forth.”
Surprisingly (with Visual Studio at his fingertips), Anders’ approach to debugging was surprisingly similar to Guido van Rossum’s: “My primary debugging tool is Console.Writeline. To be honest I think that’s true of a lot of programmers. For the more complicated cases, I’ll use a debugger … But quite often you can quickly get to the bottom of it just with some simple little probes.”
UML, Ivar Jacobson, Grady Booch, and James Rumbaugh
As I mentioned, the UML interview was too big, but a good portion of it was the creators talking about how UML itself had grown too big. Not just one or two of them — all three of them said this. :-)
I’m still not quite sure what exactly UML is: a visual programming language, a specified way of diagramming different aspects of a system, or something else? This book is about programming languages, after all — so how do you write a “Hello, World” program in UML? Ah, like this, that makes me very enthusiastic…
Seriously, though, I think their critique of UML as something that had been taken over by design-by-committee made a lot of sense. A couple of them referred to something they called “Essential UML”, which is the 20% of UML that’s actually useful for developers.
Ivar notes how trendy buzzwords can make old ideas seem revolutionary: “The ‘agile’ movement has reminded us that people matter first and foremost when developing software. This is not really new … in bringing these things back to focus, much is lost or obscured by new terms for old things, creating the illusion of something completely new.” In the same vein, he says that “the software industry is the most fashion-conscious industry I know of”. Too true.
Grady Booch gave some good advice about reading code: “A question I often ask academics is, ‘How many of you have reading courses in software?’ I’ve had two people that have said yes. If you’re an English Lit major, you read the works of the masters. If you want to be an architect in the civil space, then you look at Vitruvius and Frank Lloyd Wright … We don’t do this in software. We don’t look at the works of the masters.” This actually made me go looking at the Lua source code, which is very tidy and wonderfully cross-referenced — really a good project to learn from.
Perl, Larry Wall
I’ve never liked the look of Perl, but Wall’s approach to language design is as fascinating as he is. He originally studied linguistics in order to be a missionary with Wycliffe Bible Translators and translate the Bible into unwritten languages, but for health reasons had to pull out of that. Instead, he used his linguistics background to shape his programming language. Some of the “fundamental principles of human language” that have “had a profound influence on the design of Perl over the years” are:
- Expressiveness is more important than learnability.
- A language can be useful even before you have learned the whole language.
- There are often several good ways to say roughly the same thing.
- Shortcuts abound; common expressions should be shorter than uncommon expressions.
- Languages make use of pronouns when the topic of conversation is apparent.
- Healthy culture is more important than specific technology to a language’s success.
- It’s OK to speak with an accent as long as you can make yourself understood.
There are many others he lists, but those are some that piqued my interest. Larry’s a big fan of the human element in computer languages, noting that “many language designers tend to assume that computer programming is an activity more akin to an axiomatic mathematical proof than to a best-effort attempt at cross-cultural communication.”
He discusses at length some of the warts in previous versions of Perl, that they’re trying to remedy with Perl version 6. One of the interesting ones was the (not so) regular expression syntax: “When Unix culture first invented their regular-expression syntax, there were just a very few metacharacters, so they were easy to remember. As people added more and more features to their pattern matches, they either used up more ASCII symbols as metacharacters, or they used longer sequences that had previously been illegal, in order to preserve backward compatibility. Not surprisingly, the result was a mess … In Perl 6, as we were refactoring the syntax of pattern matching we realized that the majority of the ASCII symbols were already metacharacters anyway, so we reserved all of the nonalphanumerics as metacharacters to simplify the cognitive load on the programmer. There’s no longer a list of metacharacters, and the syntax is much, much cleaner.”
Larry’s not a pushy fellow. His subtle humour and humility are evident throughout the interview. For example, “It has been a rare privelege in the Perl space to actually have a successful experiment called Perl 5 that would allow us try a different experiment that is called Perl 6.” And on management, “I figured out in the early stage of Perl 5 that I needed to learn to delegate. The big problem with that, alas, is that I haven’t a management bone in my body. I don’t know how to delegate, so I even delegated the delegating, which seems to have worked out quite well.”
PostScript, Charles Geschke and John Warnock
My experience with Forth makes me very interested in PostScript, even though it’s a domain-specific printer control language, and wasn’t directly inspired by Forth. It’s stack-based and RPN, like Forth, but it’s also dynamically typed, has more powerful built-in data structures than Forth, and is garbage collected.
One thing I wasn’t fully aware of is how closely related PostScript is to PDF. PDF is basically a “static data structure” version of PostScript — all the Turing-complete stuff like control flow and logic is removed, but the fonts, layout and measurements are done exactly the same way as PostScript.
Some of the constraints they relate about implementing PostScript back in the early days are fascinating. The original LaserWriter had the “largest amount of software ever codified in a ROM” — half a megabyte. “Basically we put in the mechanism to allow us to patch around bugs, because if you had tens of thousands or hundreds of thousands of printers out there, you couldn’t afford to send out a new set of ROMs every month.” One of the methods they used for the patching was PostScript’s late binding, and its ability to redefine any operators, even things like the “add” instruction.
John Warnock mentions that “the little-known fact that Adobe has never communicated to anybody is that every one of our applications has fundamental interfaces into JavaScript. You can script InDesign. You can script Photoshop. You can script Illustrator with JavaScript. I write JavaScript programs to drive Photoshop all the time. As I say, it’s a very little-known fact, but the scripting interfaces are very complete. They give you real access, in the case of InDesign, into the object model if anybody ever wants to go there.” I wonder why they don’t advertise this scriptability more, or is he kind of being humble here?
I didn’t realize till half way through that the interviewees (creators of PostScript) were the co-founders of Adobe and are still the co-chairmen of the company. The fact that their ability extends both to technical and business … well, I guess there are quite a few software company CEOs that started as programmers, but I admire that.
Weird trivia: In May 1992, Charles Geschke was approached by two men who kidnapped him at gunpoint. The long (and fascinating) story was told five years later when the Geschkes were ready to talk about it. Read it in four parts here: part one, part two, part three, and part four.
Eiffel, Bertrand Meyer
Eiffel, you’re last and not least. Eiffel is quite different from Java or C#, though it influenced features in those languages. It incorporates several features that most developers (read: I) hadn’t heard of.
Design by Contract™, which Microsoft calls Code Contracts, is a big part of Eiffel. I’m sure I’m oversimplifying, but to me they look like a cross between regular asserts and unit tests, but included at the language level (with all the benefits that brings). Bertrand Meyer can’t understand how people can live without it: “I just do not see how anyone can write two lines of code without this. Asking why one uses Design by Contract is like asking people to justify Arabic numerals. It’s those using Roman numerals for multiplication who should justify themselves.”
He does have a few other slightly extreme ideas, though. Here’s his thoughts on C: “C is a reasonably good language for compilers to generate, but the idea that human beings should program in it is completely absurd.” Hmmm … I suspect I’d have a hard time using Eiffel on an MSP430 micro with 128 bytes of RAM.
It appears that Eiffel has a whole ecosystem, a neat-looking IDE, company, and way of life built around it. One of the few languages I know of that’s also a successful company in its own right. It’d be like if ActiveState was called “PythonSoft” and run by Guido van Rossum.
The end
That’s all folks. I know this falls in the category of “sorry about the long letter, I didn’t have time to write a short one”. If you’ve gotten this far, congratulations! Please send me an email and I’ll let you join my fan club as member 001.
Seriously though, if you have any comments, the box is right there below.
21 January 2013 by Ben
13 comments
Read more articles …

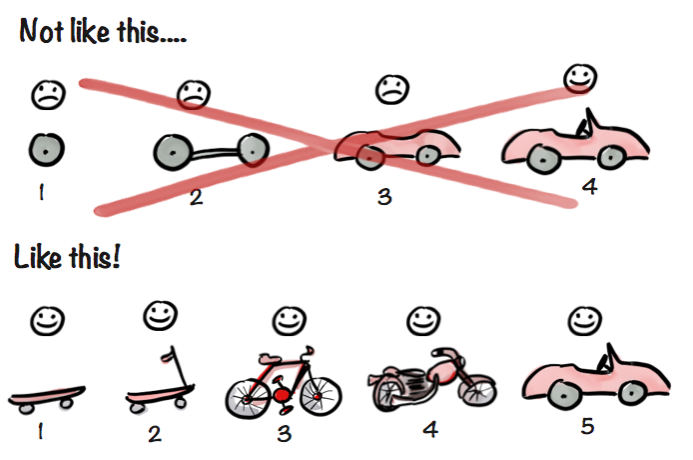



 [unleashing their people power] as they have fun while being the best. [A] small change made on the salesroom floor — by a teenage sales rep … acting on a thought to increase outreach. [O]ur economic success increasingly turns on harnessing the creative talents of each and every human being.
[unleashing their people power] as they have fun while being the best. [A] small change made on the salesroom floor — by a teenage sales rep … acting on a thought to increase outreach. [O]ur economic success increasingly turns on harnessing the creative talents of each and every human being.




{kind=link}